
You’re not totally sure how to pytorch check if GPU is available? Don’t worry! It’s pretty straightforward to check for an available GPU in PyTorch with just a couple lines of code.
PyTorch offers two ways to check GPU availability : torch.cuda.is_available() for a simple True/False answer and torch.device(‘cuda’) for a device object (raises error if unavailable).
In this quick guide, we’ll walk through exactly how to check if a GPU is available when using PyTorch step by step. Let’s dive in!
How to Check for CUDA GPU Availability?
To use PyTorch with GPU support, you’ll need an NVIDIA GPU with CUDA installed. First, check if you have an NVIDIA GPU on your system. Open your control panel and look for the NVIDIA control panel. If it’s there, you likely have an NVIDIA GPU. Another way to do this is by opening a terminal window and run:
lspci | grep -i nvidiaThis will list details of your NVIDIA GPU if detected.
Next, you’ll need to install the CUDA toolkit to get the drivers and compilers needed to run CUDA programs. Go to the NVIDIA website and download the latest version of CUDA for your system.
Once CUDA is installed, you’ll need to set some environment variables. In your terminal, run:
export CUDA_HOME=/usr/local/cuda-10.1 # path to CUDA install
export PATH=$CUDA_HOME/bin:$PATHReplace the path with where CUDA is actually installed on your system.
Finally, you can test if PyTorch can access your GPU by running this Python code:
import torch
torch.cuda.is_available()This will return True if PyTorch detects a CUDA GPU, False otherwise.
If it returns True, you can run PyTorch operations on the GPU by simply moving tensors to the GPU:
tensor = torch.rand(2, 3) # CPU tensor
tensor = tensor.cuda() # GPU tensorNow any operations on tensor will run on the GPU. Congrats, you’re all set to use PyTorch with GPU support! Let me know if you have any other questions.
Checking GPU Availability With torch.cuda.is_available()
To check if PyTorch can access a GPU, you can simply use the torch.cuda.is_available() function. It will return True or False.
Install CUDA
For PyTorch to utilize an NVIDIA GPU, you need to first install the CUDA toolkit. The version of CUDA you install depends on your GPU. You can check which version is compatible with your GPU by visiting the NVIDIA website.
Install CuDNN
In addition to CUDA, you need to install CuDNN, which is NVIDIA’s library of optimized primitives for deep learning. Make sure you install a version of CuDNN that is compatible with your CUDA version.
Install PyTorch
Now you can install PyTorch, making sure to install the version that supports your CUDA version. For example, if you have CUDA 10.1 installed, install PyTorch 1.4 or newer.
Check Availability
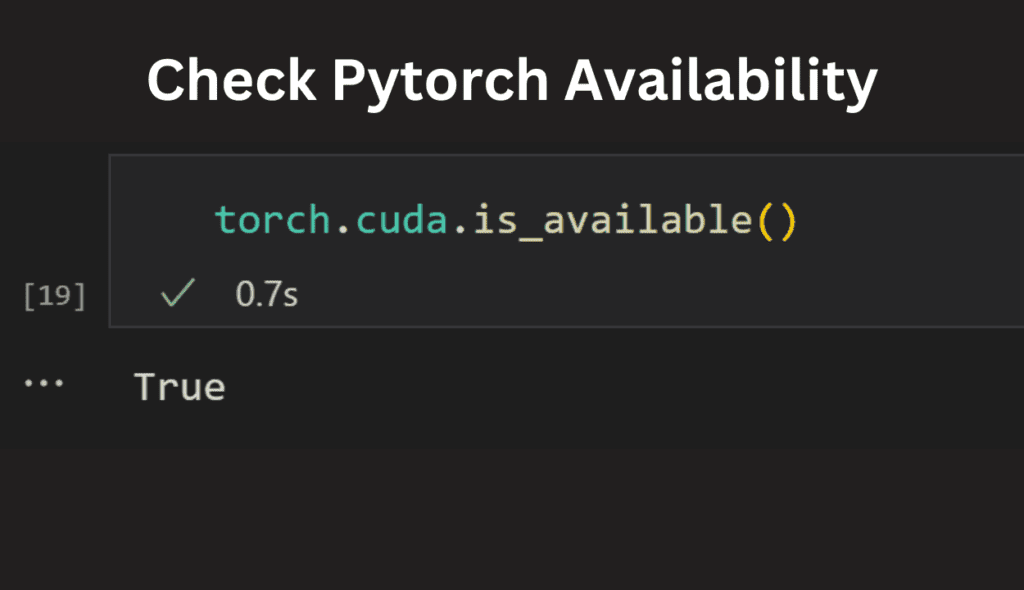
In your Python code, you can now check GPU availability with:
torch.cuda.is_available()This will return True if a GPU is available, and False if not.
Specify Device
If a GPU is available, you can specify to run operations on the GPU with:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")This will set device to “cuda” if a GPU is found, and “cpu” if not. You can then run tensors and models on the specified device.
For example:
tensor = torch.tensor(data, device=device) model.to(device)This will ensure your tensor and model utilize the GPU if one is available. If not, they will default to the CPU.
Checking for GPU availability and specifying the device in this way will allow you to write PyTorch code that can utilize a GPU if present, but default to the CPU when no GPU is found.
Setting the Device in PyTorch Code
To utilize the power of GPUs for faster training in PyTorch, you first need to check if a CUDA GPU is available. You can do this by running:
torch.cuda.is_available()This will return a boolean value indicating if CUDA is installed and a GPU is available.
Specifying the Device
Once you’ve confirmed you have a GPU, you need to specify which device you want to run your model on. You have two options:
- CUDA device (GPU):
device = torch.device("cuda")This will run operations on the GPU. If you have multiple GPUs, you can specify which GPU to use by doingdevice = torch.device("cuda:0")for GPU 0,device = torch.device("cuda:1")for GPU 1, and so on. - CPU:
device = torch.device("cpu")This will run operations on the CPU.
For example:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")This will set device to the CUDA GPU if available, else the CPU.
Sending Tensors to the Device
Once you’ve specified the device, you need to send your tensors to that device to run operations on it. You can do this by calling .to(device) on your tensors. For example:
tensor = torch.tensor([[1, 2], [3, 4]])
tensor = tensor.to(device)This will send the tensor to the device you specified, either GPU or CPU. Any operations you perform on tensor will now run on the device it was sent to.
By following these steps, you can harness the power of GPUs to speed up your PyTorch models and take advantage of the CUDA platform.
Also Read: Torch is not able to use GPU – Ultimate Guide – 2024
Moving Model and Data to GPU
Before you can leverage the power of your GPU for training neural networks in PyTorch, you need to move your model and data to the GPU. Here are the main steps to do so:
Choosing a GPU
If you have multiple NVIDIA GPUs in your system, you’ll first need to choose which one you want to use for training your model. You can view all available GPUs using:
torch.cuda.device_count()Then select a GPU using:
torch.cuda.set_device(gpu_id) Where gpu_id is the index of the GPU you want to use.
Moving Tensors to GPU
To move a tensor from CPU to GPU, simply call .to(‘cuda’) on the tensor. For example:
x = torch.tensor([1, 2, 3]) # Creates a tensor on CPU
x = x.to('cuda') # Moves tensor to GPUMoving Models to GPU
To move your neural network model to the GPU, simply call .to(‘cuda’) on your model. For example:
model = torch.nn.Linear(3, 1) # Creates a model on CPU
model = model.to('cuda') # Moves model to GPUNow your model’s parameters and computations will be on the GPU.
Moving DataLoaders to GPU
If you’re using DataLoaders to feed data into your model, you’ll want to move those to the GPU as well. You can do so by setting device=’cuda’ in the DataLoader constructor. For example:
train_loader = torch.utils.data.DataLoader(train_data, device='cuda')This will automatically move your tensors to the GPU as they are loaded in.
By moving your model, data, and DataLoaders to the GPU, you’ll be able to leverage the power of your NVIDIA GPU for faster training of deep learning models in PyTorch! Let me know if you have any other questions.
Using PyTorch with the GPU
To utilize the power of GPUs for training neural networks in PyTorch, you first need to check if you have a CUDA-enabled GPU. In a Jupyter notebook, you can check this by running:
torch.cuda.is_available()This will return True if you have a CUDA GPU, and False if you only have a CPU.
If you do have a GPU, you’ll want to install the CUDA toolkit and CuDNN. Then, when initializing tensors or models in PyTorch, you can pin them to the GPU memory by passing a device argument:
tensor = torch.tensor(data, device='cuda') model.to('cuda')This will move your tensor and model parameters to the GPU, allowing for much faster computation.
When running models on the GPU, you’ll want to make sure you:
• Move your model to the GPU before training with model.to('cuda') • Move your inputs and targets to the GPU for each batch with inputs = inputs.to('cuda') • Use an optimizer that can utilize the GPU, like optim.SGD or optim.Adam.
You’ll immediately notice a speedup when training on GPU – often 10-50x faster than CPU training! The more powerful your GPU, the bigger the speedup.
Common Errors and How to Fix Them
When using PyTorch, you may encounter some common errors. Don’t worry, many of these issues are easy to resolve.
1. “RuntimeError: CUDA device is available but out of memory”
This error occurs when you try to use a GPU but it doesn’t have enough memory for your task.
Solutions:
- Reduce the batch size: This requires less memory per operation.
- Reduce the size of your model: Consider pruning or using a smaller model architecture.
- Move to CPU: If your GPU memory is exhausted, temporarily use the CPU.
- Upgrade your GPU: This is the ultimate solution, but also the most expensive.
2. “ValueError: Expected all tensors to have the same dtype, but found dtype[0]=torch.float32 and dtype[1]=torch.float64”
This error occurs when you try to combine tensors with different data types (e.g., float32 and float64).
Solutions:
- Convert all tensors to the same data type: Use operations like
tensor.float()ortensor.double(). - Ensure consistent data types: Check your data preprocessing and model definition for inconsistencies.
3. “IndexError: Dimension out of range (expected to be in range of 0 to 0, but got x)”
This error indicates you’re trying to access an element outside the tensor’s dimensions.
Solutions:
- Double-check your indexing: Ensure you’re referencing the correct axis and index values.
- Print tensor shapes: Use print(tensor.shape) to understand the tensor’s dimensions.
- Reshape your tensor: If necessary, use
tensor.reshape()to adjust the dimensions.
4. “AttributeError: ‘module’ object has no attribute ‘your_attribute'”
This error means you’re trying to access an attribute that doesn’t exist in the module.
Solutions:
- Check the documentation: Consult the PyTorch documentation or source code for available attributes.
- Typo check: Ensure you haven’t misspelled the attribute name.
- Verify correct class/module: Make sure you’re using the correct class or module where the attribute exists.
5. “OSError: No CUDA GPUs are available”
This error occurs when you try to use the GPU but none are available or functioning properly.
Solutions:
- Verify GPU drivers: Ensure your GPU drivers are up-to-date and compatible with PyTorch.
- Check CUDA installation: Confirm that CUDA is correctly installed and configured.
- Use CPU: If no GPUs are available, temporarily switch to CPU calculations.
Also Read: Error Occurred on GPUID: 100 | Causes and Solutions
These are just a few common errors you might encounter in PyTorch. Remember to always check the error message carefully and search for solutions online using specific keywords related to the error. Additionally, consulting the PyTorch documentation and community forums can be invaluable for troubleshooting and understanding specific error scenarios.
FAQs
How do I check if a GPU is available in PyTorch?
There are two main ways:
torch.cuda.is_available(): ReturnsTrueif a GPU is available,Falseotherwise.torch.device('cuda'): Tries to create a device object on the GPU. Raises an error if unavailable.
Why do I need to check if a GPU is available?
- Using a GPU can significantly speed up PyTorch computations. Checking availability helps decide between using the GPU for faster training or the CPU if no GPU is present.
What if I get an error saying “CUDA out of memory”?
- This means your GPU doesn’t have enough memory for your task. Try reducing batch size, model size, or switching to CPU temporarily.
What if I get an error about different data types (e.g., float32 vs. float64)?
- Ensure all tensors you’re working with have the same data type. Use
tensor.float()ortensor.double()to convert them.
What if I get an error about accessing elements outside the tensor’s range?
- Double-check your indexing and tensor dimensions. Use
print(tensor.shape)to understand the tensor’s size and valid indexing ranges.
What if I have multiple GPUs, can I choose which one to use?
- Yes! Use
torch.cuda.set_device(device_id)wheredevice_idis the index of the desired GPU.
My computer has a GPU but PyTorch says none are available. What’s wrong?
- Check if your GPU drivers are up-to-date and compatible with PyTorch. Also, ensure CUDA is correctly installed and configured.
What are some alternative ways to speed up PyTorch computations besides using a GPU?
- Reduce model complexity: Use smaller architectures or prune unnecessary layers.
- Optimize data loading: Use efficient data loaders and avoid unnecessary data transformations.
- Utilize mixed precision training: Leverage libraries like NVIDIA Apex for FP16 training with reduced memory requirements.
Are there any online resources for PyTorch troubleshooting and error messages?
- Yes! The official PyTorch documentation, community forums, and Stack Overflow are valuable resources for finding solutions to specific errors.
Is there a way to automatically check for GPU availability in my PyTorch code?
- You can use a conditional statement based on
torch.cuda.is_available()to dynamically adjust your code based on GPU availability.
What are the performance differences between using a GPU and CPU in PyTorch?
- GPUs can offer significant speedups, especially for large datasets and complex models. However, the exact performance gains depend on your specific hardware and workload.
Conclusion
- That’s it, you now know several ways to check if a GPU is available when using PyTorch! Whether you want a simple boolean check or more detailed info on your GPU, PyTorch makes it easy.
- Just remember to import torch first, then you can use
torch.cuda.is_available()ortorch.cuda.device_count()to check for GPUs. And don’t forget about printingtorch.cuda.get_device_name()to see the name of your GPU device. - With these handy PyTorch functions, you’ll always know if a GPU is ready to accelerate your deep learning models. So go ahead and put your GPU to work – happy coding!